

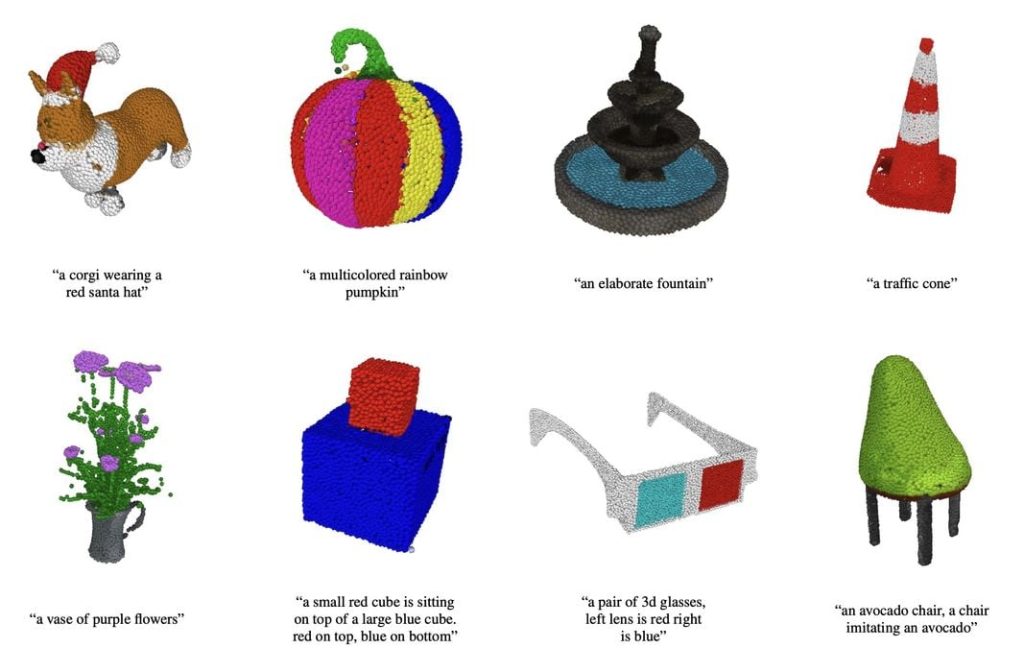
Things are moving very quickly in the text to 3D model AI space.
My speculative story from this past June discussed a step beyond mere “text to image” AI software and contemplated a more advanced “text to 3D” capability. Little did I know that it would appear in reality only a few months later. Last week Luma AI released a tool that can literally generate 3D printable 3D models from a text prompt.
Now OpenAI, one of the leading companies in the AI space, and the one that created GPT and DALL-E, released “Point-E”, a “System for Generating 3D Point Clouds from Complex Prompts.”
Note: a “Point Cloud” is a collection of points in 3D space that represent an object. They can easily be converted into a mesh model, like STL format, with many existing software tools.
The idea here is that a user could input simple text requests (a “prompt”) to obtain a 3D printable model, or one that could be used as a 3D asset in a game. An example prompt might be:
“An ornate victorian wooden chair, with velvet cushion”
The system would generate the 3D model in a manner similar to that which is done to create artificial images in several popular systems, such as MidJourney, DALL-E and Stable Diffusion.
How these systems work may be baffling, but a simple way to understand them is to compare it to something everybody has seen: Google search autocomplete. As you type, the system attempts to predict the following letters and words based on prior training.
In the image generation systems they start with just a noise image and predict what the pixels should be, over and over until an image appears. The process is called “Diffusion”, and often the results can be extraordinarily detailed and insightful. Point-E does the same, except in 3D mode.
Text to 3D has been done previously, but the processing required to complete the work takes a very long time, even on big equipment. The new Point-E system has a new algorithm that is very significantly faster. According to the accompanying research paper, the speed is “two orders of magnitude” faster. However, the paper’s authors admit the results “falls short of the state-of-the-art in terms of sample quality”.
Nevertheless, this is an extraordinary step forward.
Looking at the sample results, we can see they are indeed crude, but there are well-recognizable shapes and appropriate colors. If you look close you can see the 3D objects are in fact collections of points that have been expanded to fake out a solid structure for viewing purposes.
OpenAI has provided the code for Point-E for free public access on GitHub.
Two training models are provided. One accepts text prompts and generates crude 3D models. The other accepts images as input and attempts to make a 3D model from them. There’s also a SDF regression model to convert the generated point clouds into meshes that can be used in CAD software.
This means that any number of ventures will take the code and attempt to build systems that can perform Text to 3D functions of various sorts. It’s likely that some will develop their own training models that could improve the quality of the results or focus on particular areas of interest.
Where is this headed? One can only expect that these systems will gradually increase in quality, speed and effectiveness. There may indeed be a day in the near future where you can ask for a detailed part and a matching 3D model will be almost instantly created for you.
At the rate this technology is changing, that might be next month.
Via OpenAI, ArXiv (PDF) and GitHub